강화학습(Reinforcementle arning)이란? 강화학습(Reinforcement learning)은 기계학습의 한 영역입니다. 에이전트(Agent)가 환경(Environment)에서 반복적인 시행착오를 통해 작업 수행 방법을 배우는 머신러닝 기법의 한 유형입니다. 행동 심리학에서 영감을 얻어 한 환경 속에서 정의된 에이전트가 현재 상태를 인식하고 선택 가능한 행동 중에서 보상을 최대화하는 행동 또는 행동 순서를 선택하는 방법을 말합니다.
강화학습은 게임이론, 제어이론, 운용과학, 정보가론, 시뮬레이션 기반의 최적화, 다중에이전트 시스템, 군지능, 통계학, 유전알고리즘 등의 분야에서도 활용되고 있습니다.
영어로는 Reinforcement Learning 이라고 하며, 여기서 Reinforcement는 강화, 증강이라는 뜻입니다. 조금더쉽게강화학습을전개하면경험을통해서실력을키우게됩니다. 그 행동의 결과가 자기에게 유리한 것이라면 상을 받고 불리한 것이라면 벌을 받으면서 앞으로는 어떤 선택을 하는 것이 유리한지 스스로 깨닫게 됩니다.
사람이 어떤 것을 체험을 통해 배우고 적용하는 것과 마찬가지입니다. 비지도학습과지도학습등과는달리제공되는데이터셋에의존하는것이아니라환경에서다양한행동을하고나오는결과들,즉경험을통해서데이터를쌓아서생성되는데이터를활용하는것을중점으로다룹니다.

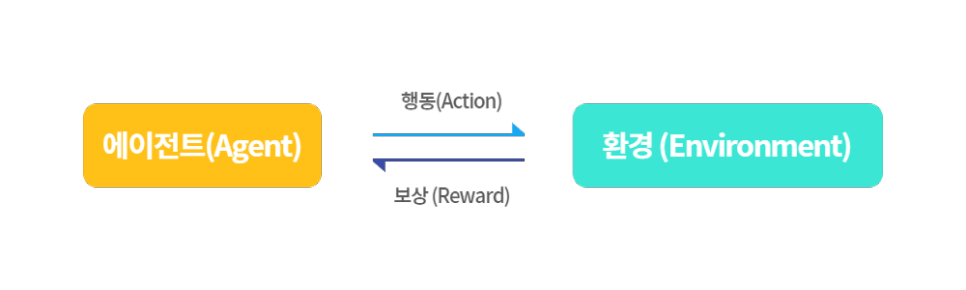
행동 (Action) 어떤 상태에서 취할 수 있는 행동을 의미합니다.상태(State) 에이전트가 행동을 하기 위해 필요한 구체적인 정보 에이전트(Agent), 어떤 행동을 선택하는 주최자 보상(Reward), 어떤 상태에서 행동을 했을 때 생기는 결과물, 에이전트가 학습할 수 있는 유일한 정보 정책(Policy), 모든 상태에서 에이전트가 어떤 행동을 해야 하는지를 결정하는 것, 목표 최적의 정책을 찾는 것(보상의 극대화는)의 극대화는 바로 그 목표 최적의 정책입니다.
예 1) 게임 GAME
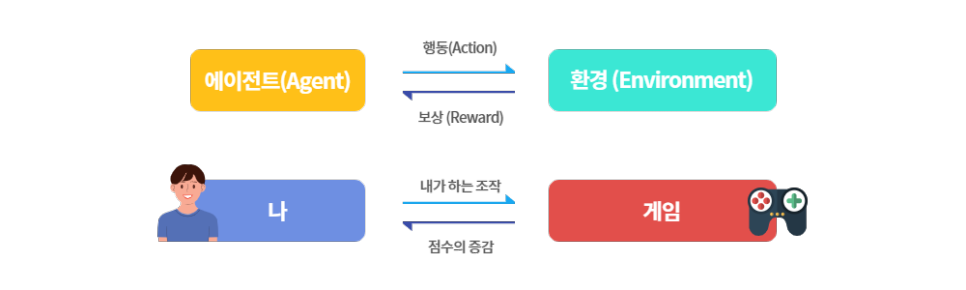
우리가 게임을 하는 주체라고 가정하면 게임을 시작하기 전에 규칙을 학습하고 어떤 방식으로 할 것인지를 쉽게 파악할 수 있습니다. 그런 다음 게임을 실제로 하면서 어떤 행동을 했을 때 점수가 깎이는지, 또 어떤 행동을 했을 때 점수가 오르고 경험치가 오르는지를 파악할 수 있습니다. 이와 같이, 게임을 하면서 어떤 상태에서는 어떤 행동을 하면 더 많은 보상을 받을 수 있는지를 파악할 수 있습니다. 게임을 거듭하면 할수록, 재빠르게 판단이 내려져 더욱 더 높은 점수와 경험치를 얻는다.
이를 강화학습으로 도입하면 ‘게임=환경(Environment)’/’게임하는나=에이전트(Agent)’/’보이는게임화면=상태(State)’/’내가 하는 조작=행동(Action)’/’점수상하=보상(Reward)’/’판단=정책(Policy)’에 해당합니다.

예2) 알파고(Alpha Go)는 2016년 3월 9일부터 15일 동안 총 5회에 걸쳐 이세돌과 알파고의 바둑 대결이 이루어졌습니다. 최고의 바둑 인공지능 프로그램과 바둑의 최고 실력자 간의 대결로 큰 주목을 받았습니다 결과적으로는 알파고가 4승 1패로 이세돌에게 승리했습니다 당시 이 강대국은 많은 사람들에게 인공지능이 인간의 수준을 넘어설 수 있다는 생각을 심어주면서 충격에 휩싸였습니다. 이 알파고에도 강화학습의 원리가 적용되었습니다. 바둑은 우주 전체에 존재하는 수소 원자의 수보다 많다는 표현이 쓰일 정도입니다.
당연히 경우의 수를 많이 알고 있는 사람, 그러니까 이기는 수를 많이 파악해서 전세를 쥐고 흔드는 사람이 우승이라고 할 수 있습니다. 알파고가이경우의수를학습하는것으로강화학습이적용되었습니다.
이것도마찬가지로기본바둑규칙을익히고나서일단많이해보고스스로수를학습하는것이필요했습니다. 이세돌이 바둑을 둔 세월을 앞지를 정도로 알파고가 현명해진 이유는 사람이 많은 게임을 하면서 체력적으로 소모되기 때문에 쉬는 시간이 필요합니다. 알파고는 기계 때문에 쉬는 시간 없이 빠르게 많은 경기를 할 수 있었기에 승리가 가능했다고 할 수 있습니다.

예3) AITOM-AI 끝말잇기 현재 AITOM에서 제공 중인 AI 학습 서비스 중 [AI 끝말잇기]에 강화학습 원리가 적용되었습니다. [AI 끝말잇기]의 경우는 총 3단계의 학습 단계를 거쳐 최종 단계인 4단계에서 자신이 만든 끝말잇기 AI를 친구들의 AI와 경쟁할 수 있도록 구성되어 있습니다.
그 중 3단계로 강화학습이 적용됐습니다. 최종 목표는 단연코 친구 AI와 경기할 때 AI가 승리하는 겁니다. 이러한 목표를 이루기 위해서 먼저 1단계와 2단계 게임을 통해서 AI가 단어를 학습할 수 있도록 도와드립니다.
게임으로 구축된 단어의 데이터를 기반으로 3단계는 자신이 단어를 학습시킨 AI가 스스로를 복제해 싸웁니다. 이때 하나의 키워드로 여러 번 게임을 하면서 그 단어가 키워드일 때 어떤 단어를 이야기하면 이기는지 스스로 파악할 수 있습니다. 예를 들어 [강화학습] – [습기] – [기만] – [만석자]로 끝났다면, AI는 스스로 게임에서 ‘만석자’라는 단어를 제시하면 승리의 리워드를 가질 수 있다는 것을 알게 됩니다. 이런점을파악하고나서4단계에서는AI와의대결에서만에서부터시작되는단어를제시할때,알고있는여러가지로만시작되는단어중에서이기위해서만석사람을제시를합니다.
1단계와 2단계에서 단어를 풍부하게 넣는 것도 중요하지만 일명 한방 단어인 나트륨 마그네슘 상인 이런 단어를 배워야 이기기 때문에 그 단어를 전단계에서 미리 학습시키는 것이 중요합니다.
오늘은 이렇게 강화학습이 무엇인지에 대해서 알아봤습니다.AITOM의 AI 끝말잇기도 강화학습의 원리를 게임을 하면서 배울 수 있기 때문에 교육에 유용하게 쓰일 수 있을 것 같으니 반에서 최고의 AI를 만들어내는 강자를 가려내는 재미있는 활동수업을 구성해 보는 것도 좋을 것 같습니다.:)
▲문의= 전화 070-4161-9712 문의메일 [email protected]

초중등 AI 교육 플랫폼, AITOM!
