#opencv #python #COCO #object_detection #custom_detection #사물인식 #image #video #processing #py #tensorflow #keras #Juppyter_notebook
안녕하세요 진우의 집에서 진우를 맡고 있는 진우입니다.
오늘은 Github의 소스를 참고하여 학습된 Parameteror 학습을 통해 만든 Parameterset을 통해 사진&영상으로 ObjectDetection 하는 것을 소개합니다.
순서를 설명하자면 Imagedataset 모으기, Labeling, 학습하기, 학습된 Parameter, Test 순입니다.
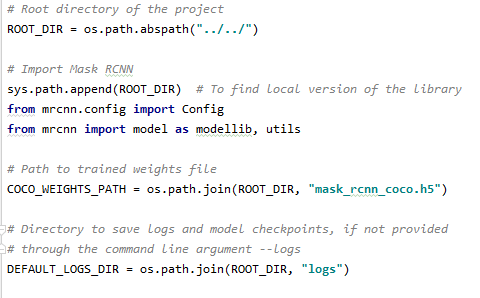
먼저 AI 학습을 통해 영상이나 이미지에서 물체를 인식하기 위해서는 가장 먼저 인식하고자 하는 물체가 무엇인지 알아야 하고 컴퓨터에 이 물체(객체)의 정보를 인식시켜 학습하기 위해서는 사진에서 해당 객체만 모아 수많은 Dataset을 만든 후 학습해야 합니다.학습할 모델을 선택해야 하는데 활용 용도에 따라 Compute 속도가 빠른 YOLO, SSD 등의 모델을 사용할 수도 있고 보다 정확한 Detection을 위해 MRCN 모델을 사용할 수도 있습니다. 저는 MRCN(MaskRCN) 모델(resnet50) 깊이를 통해 학습할 것이고 직접 학습 모델을 만들어 봐도 되지만 일단 MRCN 모델을 사용하기로 했습니다. 이후 실시간 detection에서는 mobile_faster_rcnn을 활용해 보았습니다.모델에 Data set을 넣고(MRCNCOCO 모델의 경우 xml가 아닌 json 형태의 Labeling & Class 정보가 있는 파일로 학습함) 학습을 시작하면 모델을 통해 학습을 하고 이때 tensorflow-gpu가 호출되어 CPU보다 병렬 처리 성능에서 훨씬 뛰어난 성능을 가진 GPU(그래픽 카드)가 해당 계산 작업(LOSS를 구하는 Back-Propagation)을 수행합니다. 학습이 끝나면 .h5 확장자의 로그 파일(Parameter Weight)이 생성됩니다.* 여기서 json 형식의 파일은 Labeling 하고 나온 각 객체의 polygon 형식 좌표값을 json 형식으로 저장해 놓은 파일입니다.생성된 log 파일을 통해 Git로 수신한 MRCN 코드 Sample을 변형하여 자신이 직접 Class를 분류한 댐체 인식을 수행할 수 있습니다.저는 자동차와 관련된 자율주행이나 모바일 앱 이미지 프로세싱 분야에 관심이 있어 사람의 얼굴 인식과 자율주행 시 필요한 차선, 자동차 등을 인식하는 작업을 해봤습니다.
지금부터 처음부터 하나씩 차례로 저의 작업 순서를 소개하도록 하겠습니다.저의 작업환경은 다음과 같습니다.OS : Windows GPU : GTX960 (4G) RAM : 16 GPackage : Tensorflow-GPU 1.14.0ver, keras 2.1.3ver Python : 3.6.8ver IDE : Pycharm Communityver, Annotation Tool 1ver, 그림판 (Eclipse & MonoDB, Maria DB를 활용하여 dataset 관리를 쉽게 할 수도 있습니다.)
먼저 MRCN 모델을 활용하기 위해서는 Git을 통해 모델을 받아들여야 합니다.Downloads Mac OS X Windows Linux / Unix Older releases are available and the Gitsource repository is on GitHub. Latestsource Release 2.25.0 Release Notes (20-01-13) Download 2.25.0 for Windows Guiclients Gitcomes with built-in Gitk), butther everalthird…
MaskR-CNN for RCNgithub.com 위는 이미지 Object Detection and instancesegmentationon Keras and Tensor Flow-matterport/Mask_RCNgithub.com 위는 이미지 Object Detection을 위한 것이고 아래는 opencv를 이용하여 영상에서의 detection 코드가 있습니다.
상기 소스를 다운로드 한 후 jupyternotebook에서 /Mask_RCN-master/sampes/demo.ipynb에서 Demo를 수행할 수 있습니다.* jupyternotebook은 anaconda3 설치 시 자동으로 설치되며 아래와 같은 아이콘을 클릭하면 Explore 창이 뜨고 jupyternotebook이 실행됩니다.
demo.ipynb 실행 화면(저는 다른 이미지 사진을 사용했습니다.)
- 수행 결과
- 다음과 같이 사전에 학습된 파라미터 파일(mask_rcn_coco.h5)을 통해 80가지(class) 객체에 대해 묵체 인식이 가능합니다.
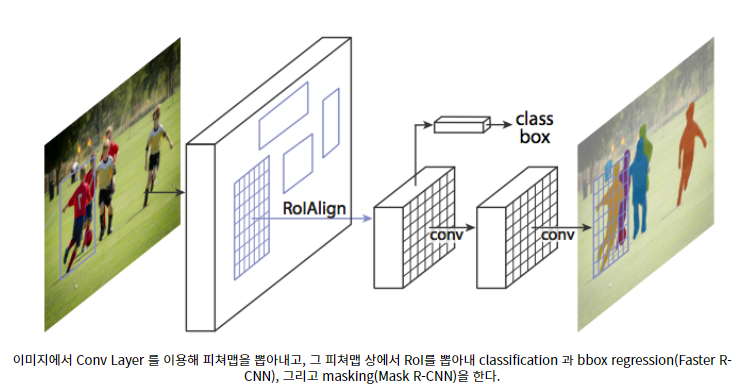
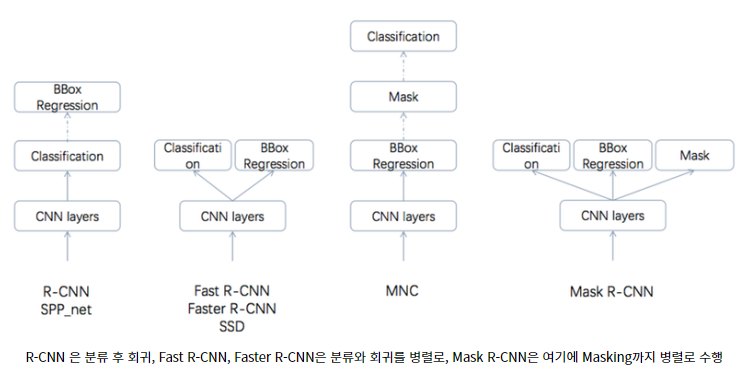
- Custom Object Detection에 앞서 MRCN에 대한 개념을 조금 살펴보겠습니다.Mask_RCN은 2014년 RCN에서 점차 모델 개선을 통해 2017년 MRCN으로 발전했고, MRCN의 전신인 Faster-RCN을 확장해 Instance Segmentation에 적용하려는 모델로 MRCN이 등장했습니다.Mask-RCN은 FasterRCN에서 각 픽셀이 객체인지 아닌지를 판별하는 CNN층(Binary Mask)을 하나 더 두었고, MRCN은 어느 모델보다 뛰어난 성능을 보였습니다.
- FasterRCN에서 MRCN이 되면서 달라진 점은 (1) “bbox 인식을 위한 브랜치”에 병렬로 “객체 마스크 예측 브랜치”를 추가하고 (2) ROI pooling 대신 ROI Align을 사용합니다.(1)기존의 FasterRCN을 Objectdetection 역할을 하도록 하고, 각각 RoI에 masksegmentation을 수행하는 FCN(FN)을 추가하였습니다.(2)FasterRCN은 Objectdetection만 하고 RoIPooling으로 객체의 정확한 위치정보는 Pooling RoIAlign으로 위치정보 왜곡방지 기법
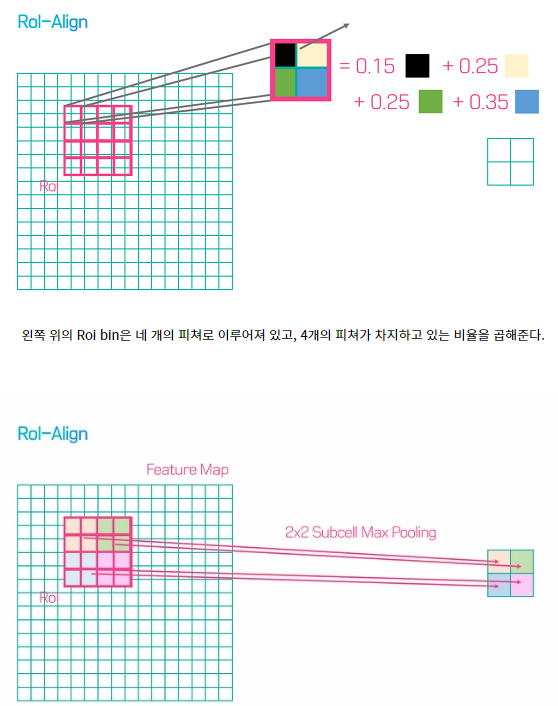
- RoIAlign 설명
- RoIA lign 설명 간단히 말하면, 각 픽셀에서의 비중을 곱함으로써 정확한 위치 정보를 가지고 Pooing하게 된다.MaskDetection에 상당한 성능 향상을 보여준다.
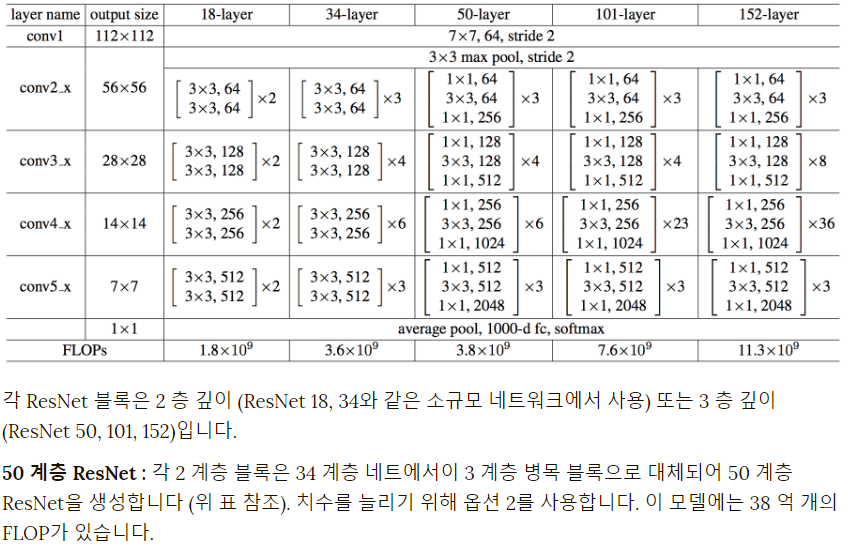
- MRCN은 resnet 네트워크를 사용하는데 네 번째 스테이지 마지막 ConvLayer에서 Feature를 추출한다.Resnet 50, Resnet 101을 주로 사용한다.

LossFunction의 경우 Classification, bboxregression, binaryMasking의 합계를 전체 Loss에서 구하는데 – classification: SoftmaxCrossEntropy-box: bboxregression-mask: BinaryCrossEntropy
네트워크의 구조 비교(RCN~MRCN)
지금부터 나만의 Custom dataset을 가지고 학습하기 위한 방법을 소개하겠습니다.Custom dataset을 이용하려면 먼저 Dataset을 모아야 합니다. 저 같은 경우에는 많은 Dataset을 모을 수 있는 환경이 아니기 때문에 차선, 자동차에 대한 이미지 데이터를 모으기 위해 웹을 이용했습니다.


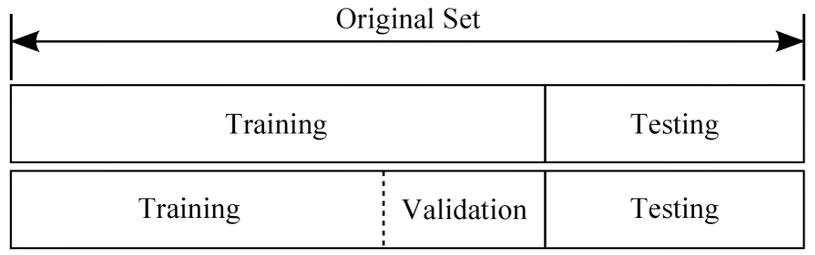
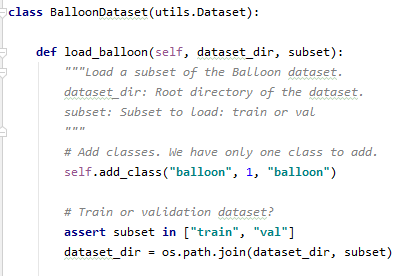
- 학습을 위해 모은 이미지를 모을 때 저장할 위치는 /Mask_RCN_master/sampes/balloon 폴더 전체를 복사하여 ‘CUSTOM’과 동일한 이름으로 변경한 후 CUSTOM 폴더 내부에 기존 dataset 폴더를 삭제한 후 dataset이라는 폴더를 생성하고 dataset 폴더 내부에 train, val 두 폴더를 저장한 후 각각의 폴더에 다른 이미지를 저장합니다.(train 폴더 이미지 수가 훨씬 많으면 좋겠다. val은 validationset이기 때문에) validationset을 ML에서 사용하는 이유는 아래 링크에서 친절하게 설명해 주었습니다.validationset은 machinelearning 또는 통계의 기본적인 개념 중 하나입니다. 하지만 실무를 할 때 귀찮은 부분 중 하나라 그냥 넘어가기도 합니다. 그냥 trainingset에서 training을 하고 test만 하면 되는데 왜 3months.tistory.com

위와 같은 사진을 여러 장 많이 모으고 컴퓨터는 눈이 없기 때문에 인식하고 학습하는 오브젝트에 대해 학습 전에 labeling(Annotation)을 해서 각 오브젝트의 위치정보를 포함하고 있는 json 형태의 파일을 추출해야 합니다.Labeling Tool은 아래 링크를 통해 진행해 주세요.RegionShapeLoadedImagesRegionAttributesFileAttributesKeyboardShortcutsLLoadimagestostartannotationor, seeGettingStarted.www.robots.ox.ac.uk(*사실상 LabelingTool이 사용하기에 불편한 점이 많아 AnnotationTool을 만드는 중입니다.)
Labeling Tool의 사용법을 간단하게 써보세요.

- Loador Add Images를 클릭하여 이미지를 표시한다.
2. CoComodel에 맞게 polygon 형태를 클릭하여 Labeling을 진행한다.
마우스를 클릭하고 틀을 따라 그린다.(사실 더 많이 그려야 한다.) (서양속담, 공부속담)

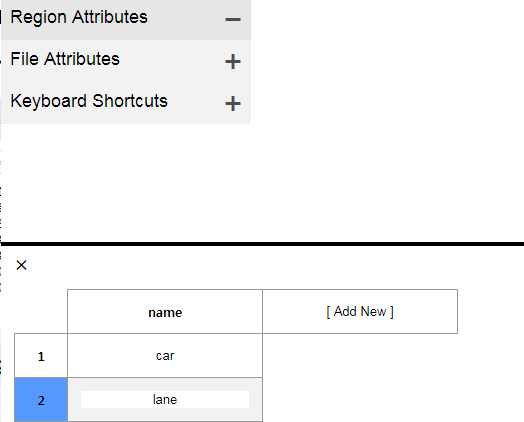
4. RegionAttributes를 클릭하여 name&class 이름을 쓴다. 반드시 RegionAttributes이어야 한다.필자는 처음에 File Attributes로 만들었지만 몰체 인식에 실패했다.
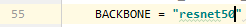
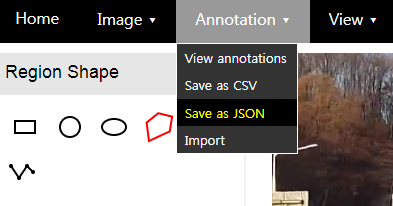
5. Annotation -> Saveas JSON으로 저장한다.반드시 json 형태로 한다. CSV 형태( , , )라고 하면 다시 퍼싱해서 json 형태로 어차피 고쳐줘야 한다.

6. 저장완료 저장을 하면 해당 이미지가 있는 폴더 내에 JSON 형태 파일이 생성된다.
- jsonfile Indenation이 맞지 않지만 대략 위와 같이 저장된다.key:File명 size:filesizeregions:Locationname:형태(Type) region_attributes의 name:name:저장한 class이름 all_points_x:polygon의 각 꼭짓점 x 좌표 all_points_y:polygon의 각 꼭짓점 y 좌표 0, 1, 2, …:1개의 image에서 그린 annotation 수(Labeling 시 하나의 이미지가 빠지거나 name이 비어있거나 약간의 문법 오류가 발생할 수 있음)
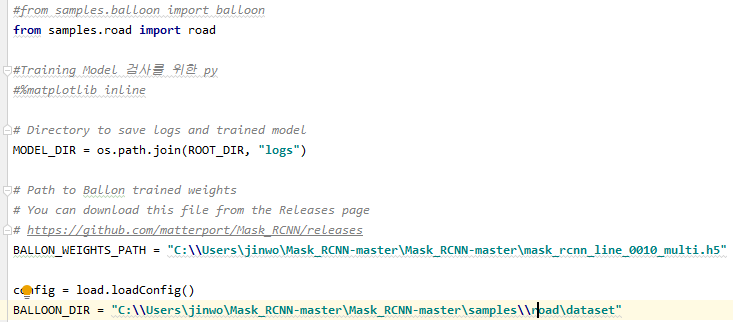
- 다음으로 할 일은 json 파일로 학습시키는 것입니다.아까 복사해 놓은 CUSTOM 폴더에 balloon이라고 쓰여졌다.py파일을 저는 헷갈리지 않도록 road.py로 이름을 변경하여 활용합니다.road.py을 열면 주석으로 설명이 적혀 있습니다. (road.py에 대한 설명과 수정사항 나열) 저는 pre_trained된 cocoweight로 학습시킬 예정이므로 나중에 anaconda 환경에서 학습할 때 사용할 명령어를 미리 아래와 같이 고쳐 놓겠습니다.
- Training 시 CMD로 띄우는 명령어 road.py에서 아래 코드는 Weight에 대한 경로 관련 코드입니다. 경로 오류 발생 시 아래 코드를 수정해 보세요.

- PATH코드 아래와 같이 절대경로로 수정하셔도 됩니다.
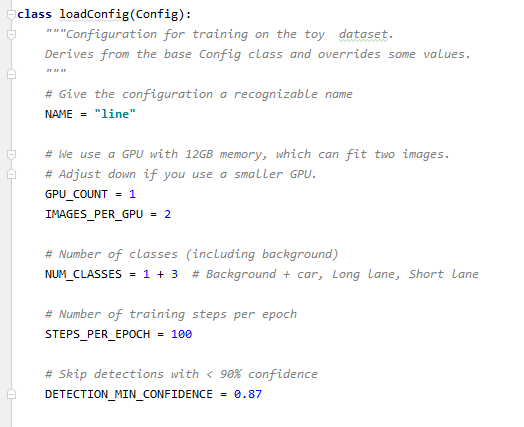
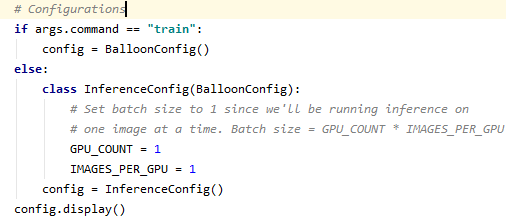
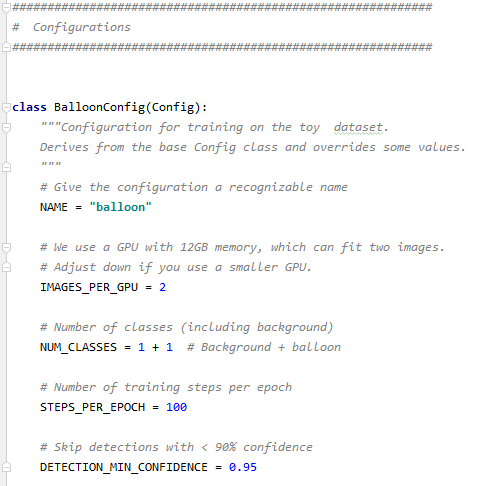
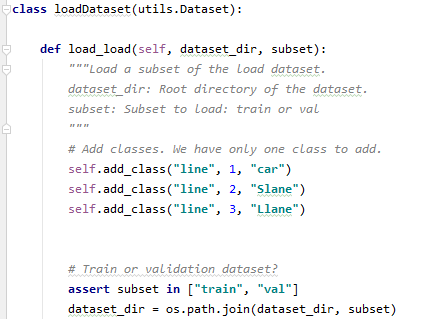
다음은 configuration 관련 코드입니다.mrcn 폴더 config.py에 Training 설정과 관련된 많은 값이 있는데 여기서는 주요 config를 설정할 수 있습니다. 저는 NAME=”line”으로 사용중인 GPU는 하나이므로 1, NUM_CLASSES는 background(기존 이미지)+CLASS 갯수만큼 필요합니다. 저는 Car, Slane, Llane 3개의 class를 labeling시 작성하였으므로 1+3이 됩니다. STEPS_PER_EPOCH1 Epoch(모든 training Data를 한번씩 이용한 것)당 Training Step 수를 결정하고 DETECTION_MIN_CONFIDENCE는 Object Detection을 할 때 해당 정확도 이상으로만 Detection 하는 것을 의미합니다.
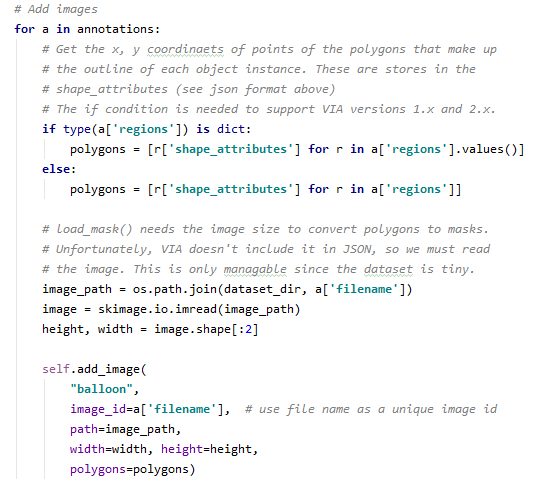
왼쪽:기존 코드/오른쪽:수정된 코드 다음은 앞서 작성한 json 파일에서 데이터를 Load 작업을 하는 코드입니다.add_class의 첫 번째 인자는 NAME과 같고 두 번째 인자는 class 번호, 세 번째 인자는 Labeling 시 작성한 이름입니다.subset 위치에 train이나 val이 있는지 assert에서 확인하고 dataset_dir에 dataset 경로를 넣습니다.
- 왼쪽: 기존 코드/우: 수정된 코드 기존 코드는 하나의 class에 대한 학습을 위한 코드이기 때문에 생성할 클래스 수에 맞게 name과 id(class 번호)를 넣는 코드를 작성했다.
- 코드 수정 전

- 코드 수정 후

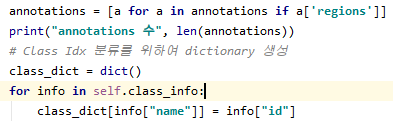
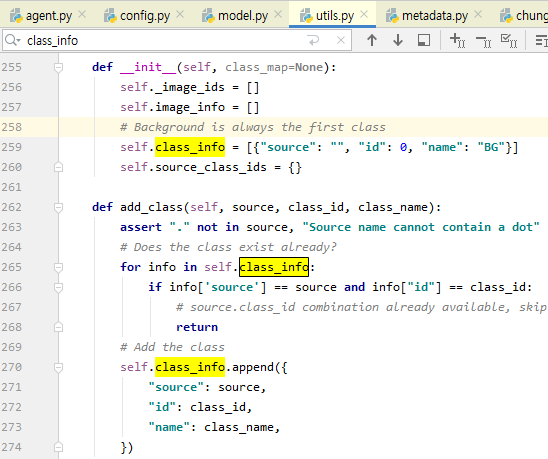
- mrcn의 utils.py상 utils.py의 일부 코드를 보면 class_info에 대한 정보를 얻을 수 있으며, class_info는 dictionary 형태로 source, id, name이 저장된다.
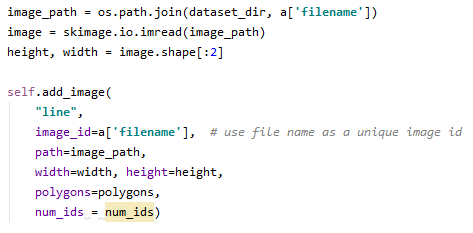
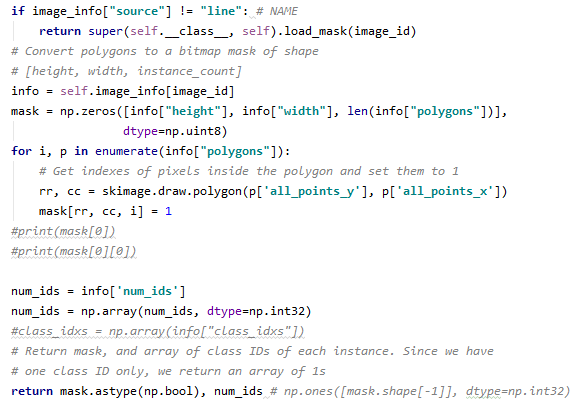
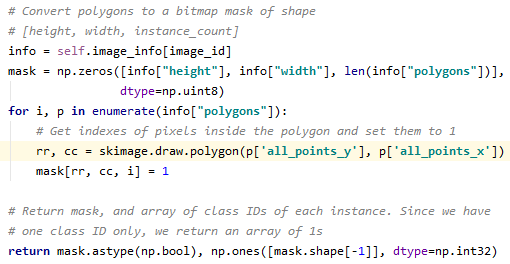
- 종래의 코드는 이미지 수만큼 folloop을 돌고 regions 좌표 정보를 polygons에 저장하고 이미지에 좌표 정보를 넣는다. 그러나 여기에서는 덤체에 대한 class 분류는 들어 있지 않으므로 코드를 다음과 같이 수정하였다.class_name을 가져와 num_ids에 각 이미지마다 class_names 값을 넣는다.
- 왼쪽 : 기존 코드 / 오른쪽 : 변경된 코드

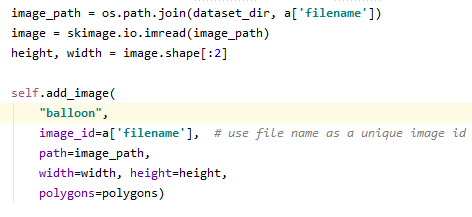
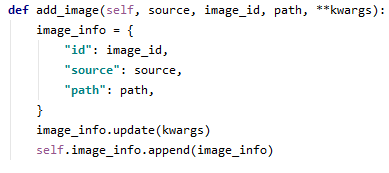
- num_ids를 인자에 넣어 self.add_image(utils.py)로 전달한다.
- utils.py 의 add_image(image_id : 파일명, source : NAME, path : 경로)

*image_info는 list 형태로 정의되어 있습니다.(utils.py) **kwargs는 키워드된 가변 개수의 인자를 함수로 보낼 때 사용하며 num_ids를 받을 수 있습니다.
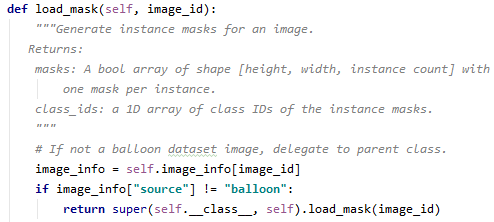
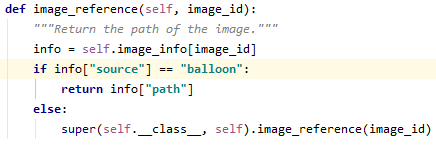
기존의 load_mask의 “balloon”을 NAME=”line”이었으므로 “line”으로 고칩니다.

기존 코드에서는 self.image_info[image_id](*image_id=해당 이미지 1장)에 class에 대한 정보가 없으며, 새 코드에서는 class 정보를 포함하는 self.image_info를 info 변수로 받아 ‘num_ids’ 값을 받고 Numpytype으로 변환 후 np.ones([mask.shape[-1], dtype=np.int32) 대신 num_ids를 return 합니다.
- 기존 코드

- 수정된 코드’balloon’을 ‘line’으로 수정
deftrain(model): 함수에서 train 폴더와 val 폴더의 Training Data set Load(가져오기)
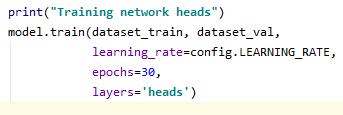
deftrain(model): 함수에서 model.py의 train 함수를 training 정보를 담아 호출합니다.<Epoch수 설정, config.py의 LEARNING_RATE 설정, layers 설정> * Learning rate : 학습을 통해 parameterupdate시 변화값의 정도를 Control * Epoch수 : 학습횟수(위에서 Epoch당 training step은 100으로 설정) * layers는 모델로 “heads”는 COCOset에서 마지막 layer에 대해서만 parameterupdate 진행 ->ex) 3+의 경우 3Layer 이후의 Param
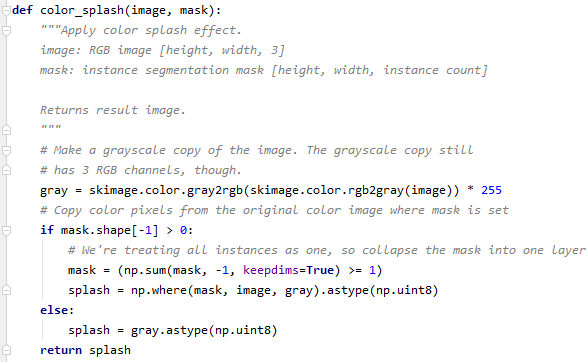
color_splash는 Detected Object에 대해 color를 붙이는 함수입니다.
BatchSize 설정 : Batchsize = GPU_COUNTxIMAGES_PER_GPU, 그리고 trainingconfig에 대한 정보를 display 해줍니다.
- batch size는 1로 설정되었다.
- 나머지 코드는 앞으로 더 분석하고 anaconda Prompt를 실행시켜 tensor flow가 설치된 가상 환경에 접속하여 training을 진행합니다. > road.py 의 directory 로 cd 명령으로 이동하여 방금 주석 처리되었던 road.py 의 train 명령어를 복사하여 실행시킵니다.
- training 코만도
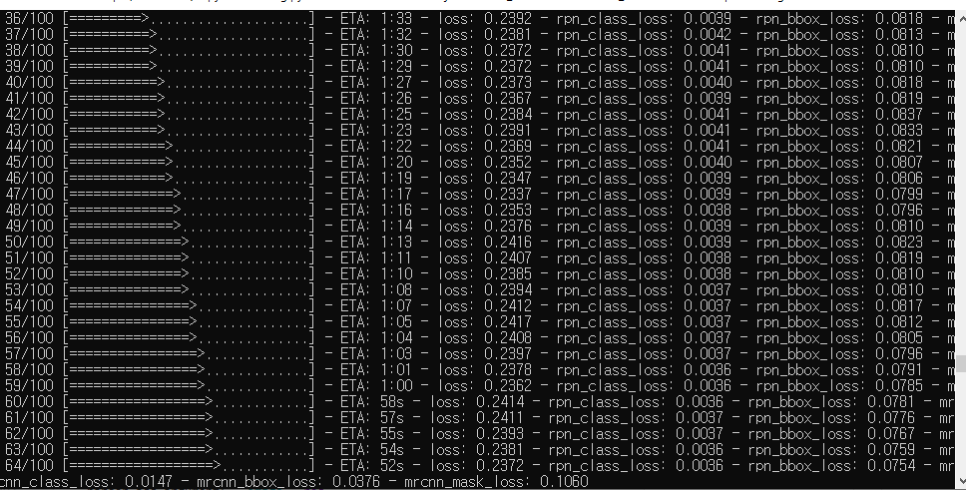
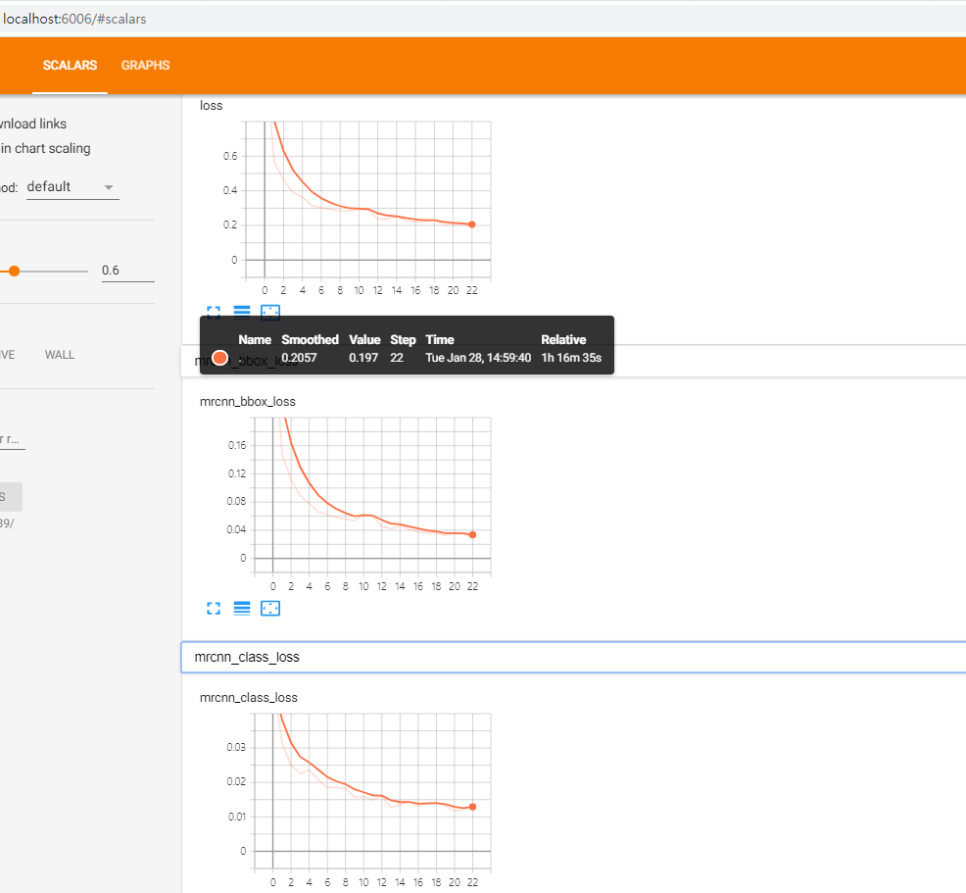
- prompt traing 실행 화면 training을 하여 cmd 창에서도 loss 값을 볼 수 있는데 tensorboard를 통해 GUI에서 training 실행 과정을 확인할 수 있으며 tensorboard를 통해 GUI에서 training 실행 과정을 확인할 수 있습니다.방법! 1. 현재 트레이닝하여 log 파일(.h5)이 생성되는 logs 폴더 directory에 cd 명령을 통해 접속합니다.2. tensorboard–logdir=./log폴더명/명령어를 통해 tensorboard를 실행합니다.제 경우 예:C:UsersjinwoMask_RCN-masterMask_RCN-masterlogs>tensorboard–logdir=./circle 2020128T1339/3. Chrome 주소창에 localhost:6006을 입력하면 아래와 같이 LOSS 그래프를 확인할 수 있습니다.

- tensorboard 실행시 cmd창
- tensorboard처럼 training이 끝나면 log 데이터로 .h5(Weight) 파일이 생성됩니다.
상기 파일을 /Mask-RCN-master 폴더에 복사합니다.
저의 .h5 파일 용량이 작은 이유는 저는 training 시 config.py에서 ‘resnet 101’이 아닌 ‘resnet 50’을 사용했기 때문입니다.(mrcnn 의 config.py )
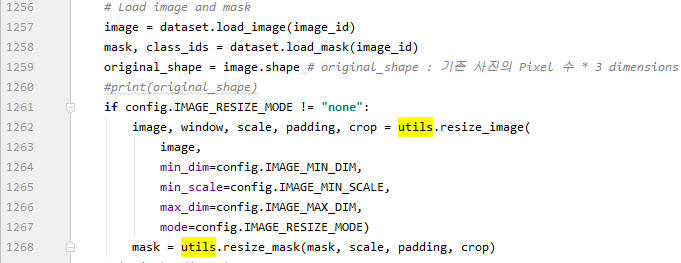
또한 Image에 대한 Resizning 여부를 설정할 수 있는데 기본이 “square”로 이미지에 대한 resizing max, min 값을 정할 수 있습니다. “none”으로 설정하면 resizing을 거치지 않고 training을 하며 이때 이미지의 픽셀이 가로 모두 2^6로 나뉘는 숫자여야 합니다.(Ex) 640×320, 960×512) 이미지 pixelsize가 2^6로 나뉘어 떨어지지 않으면 “square”, “pad64” 등을 사용하거나 dataset을 resizing하여 “none”으로 사용할 수도 있습니다.(resizing을 거쳐야 Forward Compute 시 Detection 속도가 빨라지는 것을 확인할 수 있습니다.)
아래는 model.py의 일부 코드이며, “none” 선택 시 config.py만 수정하면 되도록 하기 위해 약간의 수정을 하였습니다.

- model.py에서 학습된 model의 parameter Weight를 이용하여 ObjectDetection을 진행합니다.영상에서의 detection을 진행하기 전에, 사진(화상)에서의 detection을 먼저 실시하는 것으로 합니다.
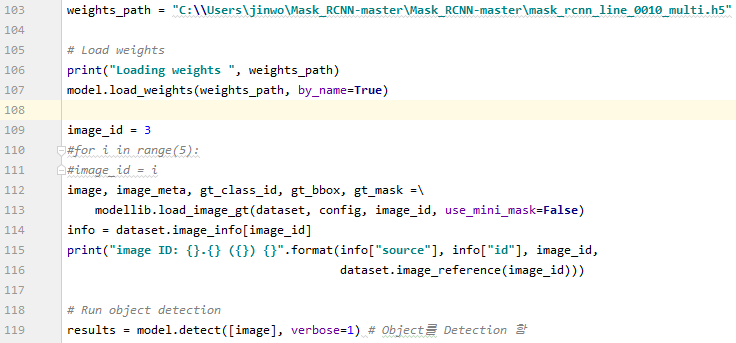
- inspect_train_image.ipynb 파일을 jupyternotebook에서 열고 소스를 Pycharm IDE로 복사해 옵니다.소스를 받은 후에 importballoon 대신에 importroad를 하고 Weightpath와 Datasetpath를 수정합니다.

mode는 test 모드에서 inference이고 gpu를 사용하므로 /gpu:0으로 작성합니다.
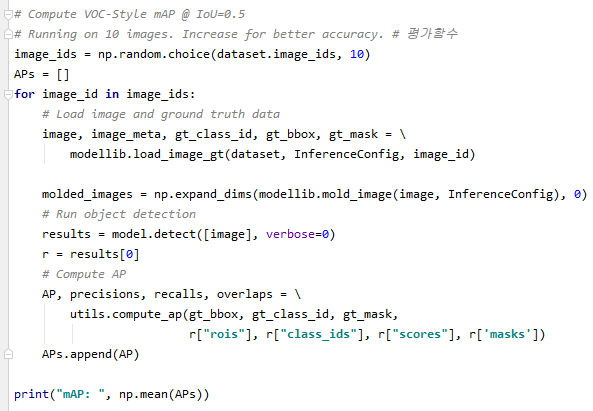
Weight를 읽고 테스트할 image를 선택합니다. (random.choice,image_id=x, forimage_idinrange(x) 등 사용)
- 이미지에 대한 detection까지 실행 하단의 코드는 추가된 평가 함수입니다. 10개의 random에 image를 빼고 테스트 후 정확도 값(평균)을 반환합니다.(np.mean=평균)
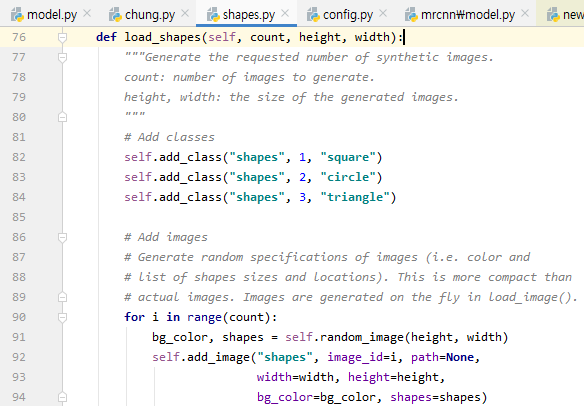
sampes 폴더의 shapes.py에서 MULD 객체 인식 힌트를 얻을 수 있습니다.
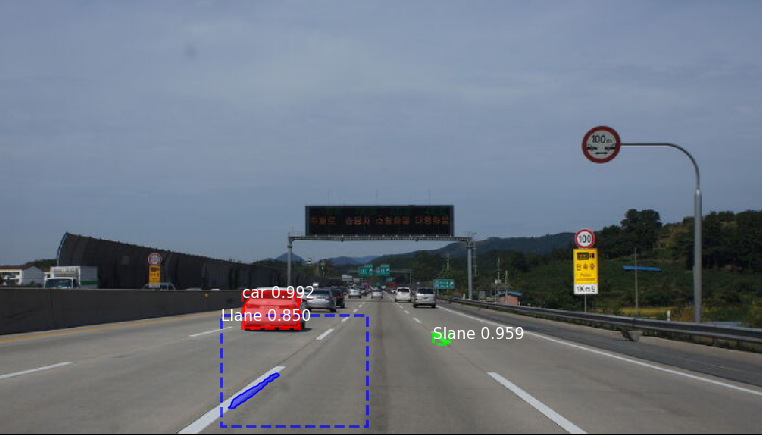
- shapes.pyCustom ObjectDetection 수행 결과

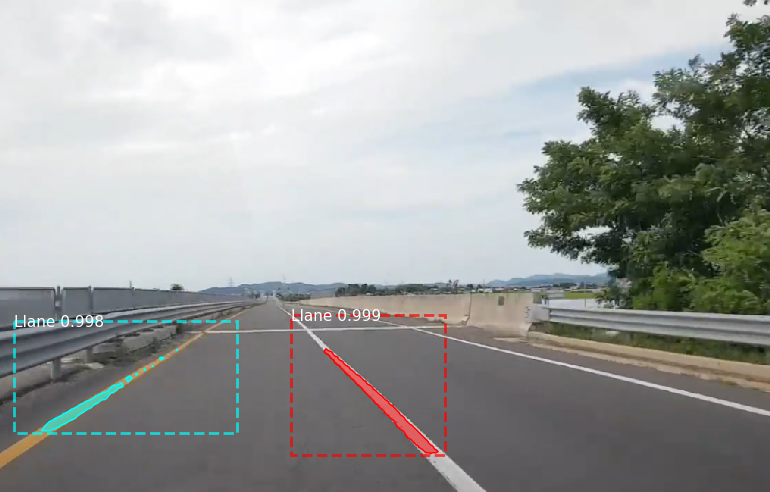
Epoch를 10번인가 돌리지 않기 때문에 정확도는 높지 않지만 더 많은 Dataset과 긴 Trainingepoch 수를 가지면 더 정확한 Detection이 가능할 것 같습니다.다음 포스팅에서는 영상에서의 Objectdetection을 소개하고 Mask_RCNN이 아닌 다른 모델을 사용한 CUSTOMObjectDetecion도 소개합니다.MRCNN의 model.py, config.py 코드 분석 소개는 다음과 같습니다.
ref https://mylifemystudy.tistory.com/82(MRCN 정리) https://3months.tistory.com/118(trainset&validationset)https ://chess72.tistory.com/132(python 경로에 관한 설명) http://github.com/jinu0124/mask_rcn_master_custom( 상기 코드 참고 책 )